Random Forests - Explained
- 7 minutes read - 1463 wordsIntroduction
A Random Forest is a supervised Machine Learning model, that is built on Decision Trees. To understand how a Random Forest works, you should be familiar with Decision Trees. You can find an introduction in the separate article Decision Trees - Explained. A major disadvantage of Decision Trees is that they tend to overfit and often have difficulties to generalize to new data. Random Forests try to overcome this weakness. They are built of a set of Decision Trees, which are combined into an ensemble model, and their outcomes are converted into a single result. As Decision Trees, they can be used for classification and regression tasks.
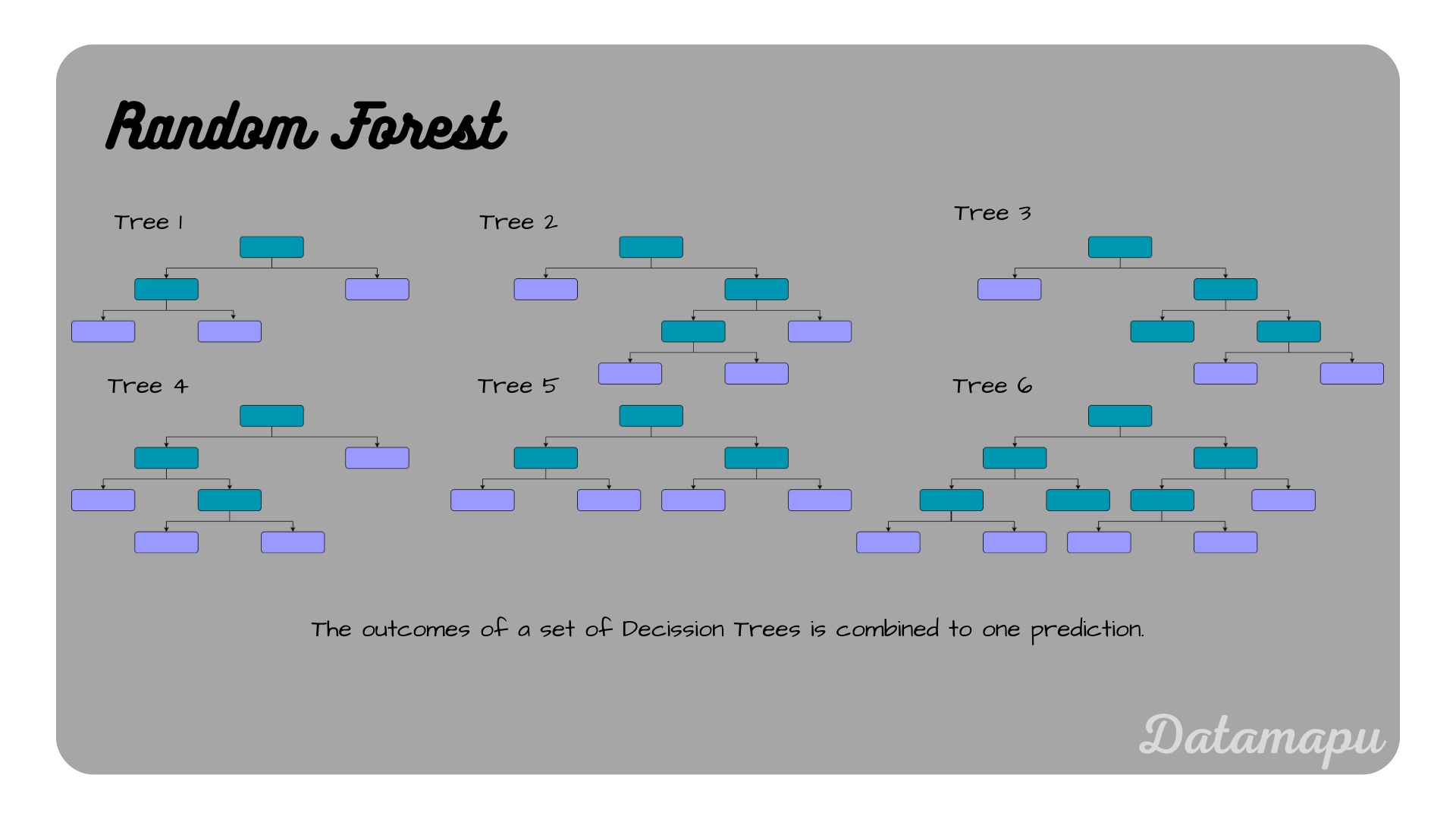 Illustration of a Random Forest.
Illustration of a Random Forest.
Build a Random Forest - The Algorithm
A Random Forest is an example of an ensemble learning method. Multiple Machine Learning models are combined to obtain a better model (’the wisdom of crowds’). More precisely it is an example of the Bagging or Bootstrap Aggregation method. The underlying models in a Random Forest are Decision Trees, in which individual outcomes are combined into one single prediction. Decision Trees are powerful Machine Learning models, which are easy to interpret. They have, however, one severe disadvantage, which is that they are prone to overfitting. Decision Trees are an example of models that have a low bias, but a high variance, especially when they are trained without pruning. This is aimed to be improved by using Bagging / Bootstrap Aggregation. The algorithm to build a Random Forest is as follows. Consider a dataset of $N$ samples and $M$ features.
- Draw $N$ samples without replacement. This is also called bootstrapping.
- Build a Decision Tree using the above drawn data samples without pruning.
- At each node use a subset $m « M$ of all possible features.
- Repeat 1-3 $d$ times.
This will result in $d$ Decision Trees, where $d$ is a hyperparameter that we need to choose. The variance compared to a single Decision Tree is reduced by using a subsample, that is drawn with replacement. This reduces the variance of the underlying dataset and therewith the variance of the Decision Tree itself. Each tree is built independently and may give different results. The final decision is then taken by considering the results of all trees developed and applying an aggregation function. In a classification problem, this aggregation function is the majority class, that is the class that was predicted by most of the trees is the final decision. In a regression task, the aggregation function is the mean of all predictions, which is the final prediction.
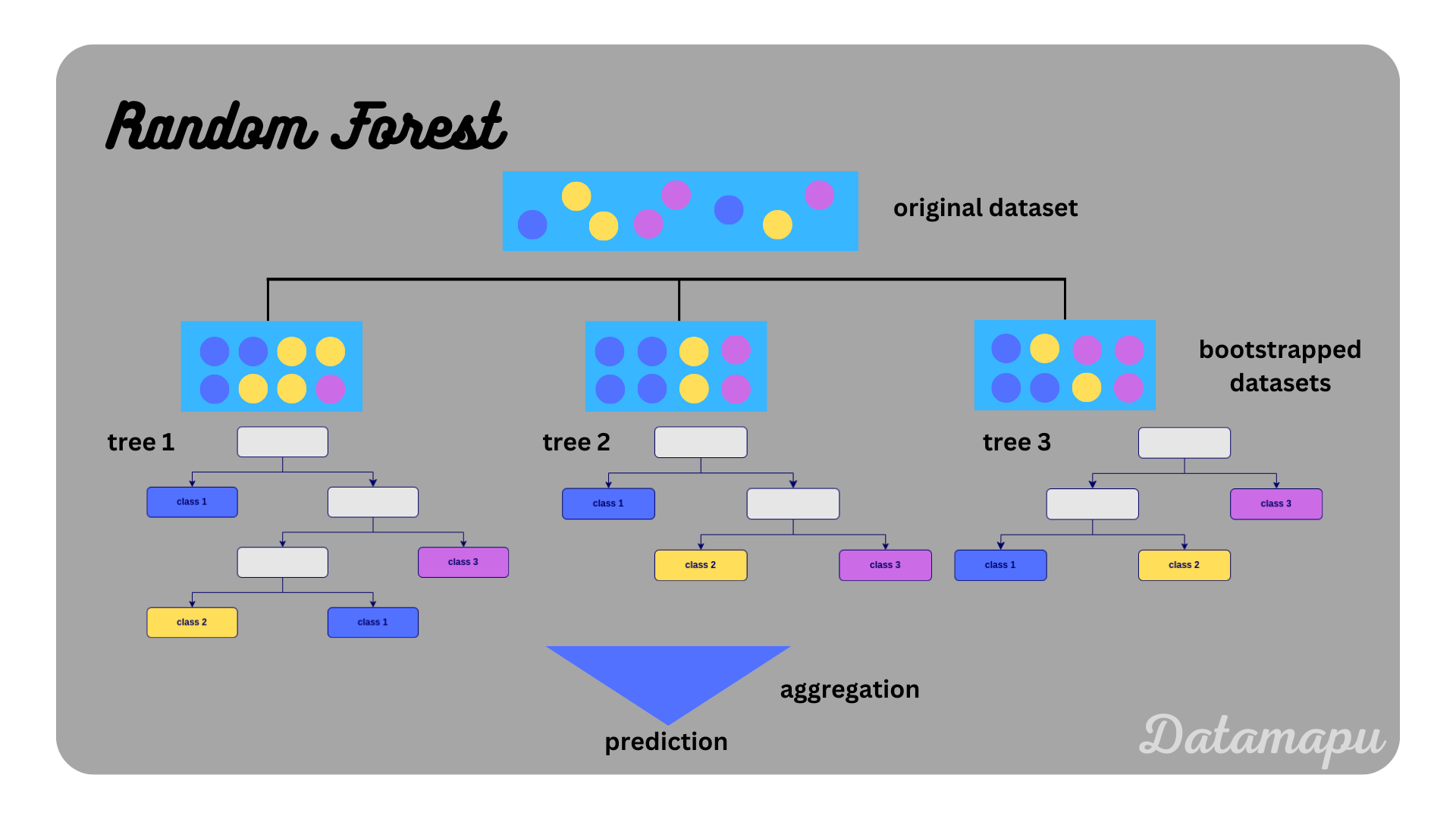 Illustration of the algorithm of a Random Forest.
Illustration of the algorithm of a Random Forest.
To improve the decision taken by a Random Forest compared to a single Decision Tree, it is important that the individual trees are as uncorrelated as possible. By not only choosing a subset of the dataset but also a subset of the possible features a second randomness is introduced, which reduces the correlation between the individual trees. The number of features $m$ used is another hyperparameter that needs to be set.
Advantages & Disadvantages
Pros
- Random Forests can be used for regression and classification problems.
- Random Forests are able to learn non-linear relationships.
- Random Forests can combine categorical and numerical variables.
- Random Forests are not sensitive to outliers and missing data.
- Scaling the data is not necessary before fitting a Random Forest.
- Random Forests balance the bias-variance tradeoff.
- Random Forests reduce overfitting compared to Decision Trees.
- Random Forests reduce the variance in the predictions compared to Decision Trees.
- Random Forests can provide information about the feature importance.
- The trees in a Random Forest are independent of each other and can be created in parallel, which makes the training faster.
Cons
- Random Forests are less interpretable than a single Decision Tree.
- Random Forests need a lot of memory because several trees are stored in parallel.
- For a large number of trees and / or a large dataset, they are expensive to train.
- Although Random Forests are less prone to overfitting, they still may overfit if too many trees are used or the trees are too deep.
Random Forests in Python
In Python, we can use the sklearn library, which provides methods for both regression and classification tasks. Below a simplified example for a classification problem is given. The constructed dataset contains only 10 samples for illustration purposes. The data describes whether a person should go rock climbing or not depending on their age, and whether or not the person likes goats and height.
| |
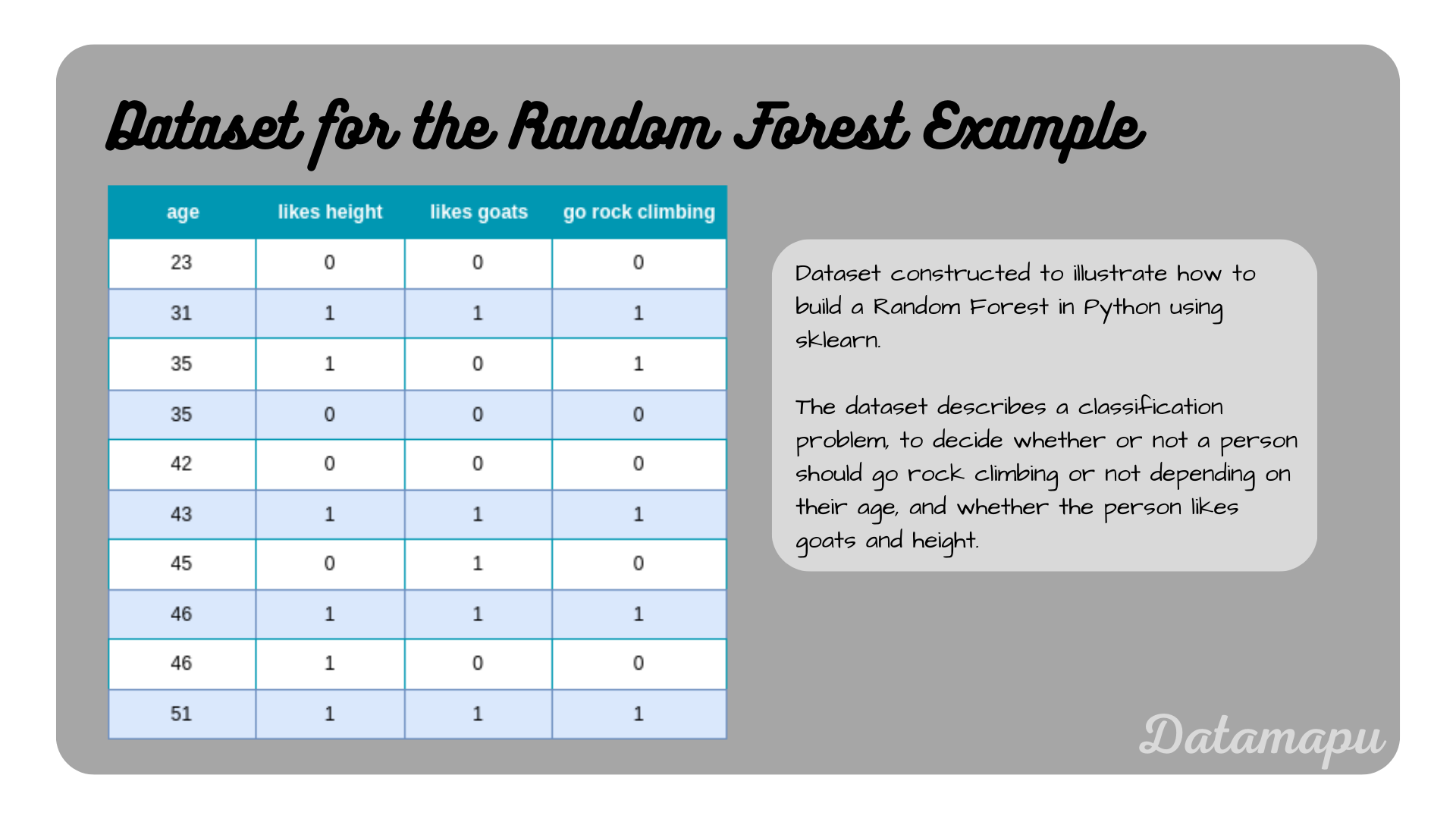 Dataset used for the Random Forest example.
Dataset used for the Random Forest example.
We now fit a Random Forest to the data using the RandomForestClassifier method provided by sklearn.
| |
In this example, the dataset is very small and it is only for illustration purposes. In sklearn a lot of hyperparameters exist to optimize a Random Forest. In the above example, we set n_estimators=3, which is the number of Decision Trees used in the Random Forest. For real-world examples, this number will be chosen higher, the default value in sklearn is $100$. Additionally, the random_state is set to make the results reproducible. We can access the individual trees in the Random Forest and plot them. The first tree can be visualized as follows.
| |
The three trees in this Random Forest are shown in the next plot.
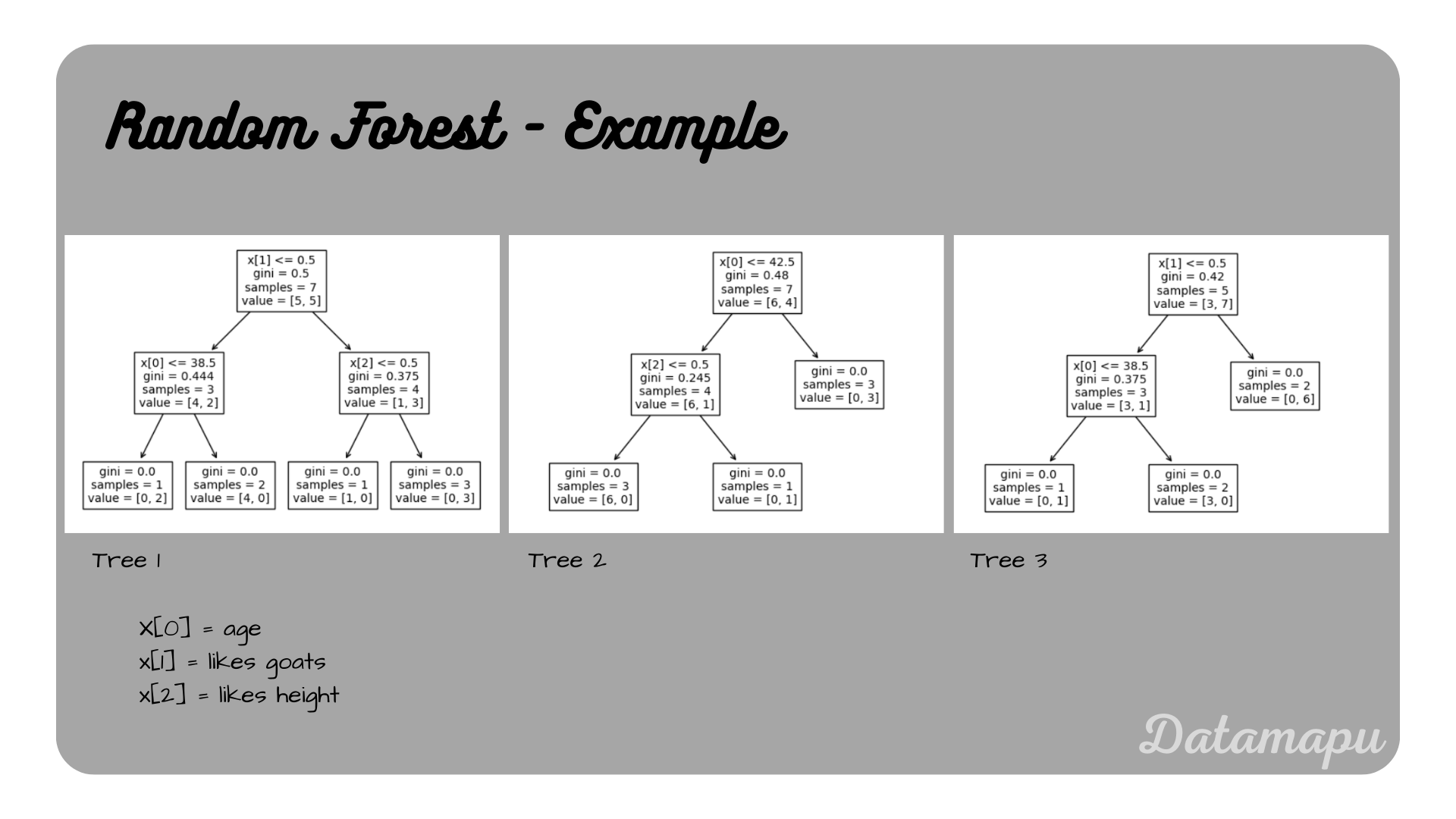 Trees in a simplified example for a Random Forest.
Trees in a simplified example for a Random Forest.
Let’s consider an example prediction. Take the second sample from the dataset: age $= 31$, likes goats $= 1$, and likes height $= 1$. Going through the Decision Trees the predictions are: tree 1: 1, tree 2: 1, tree 3: 1. The majority class is thus $1$, which is thus the prediction of the Random Forest.
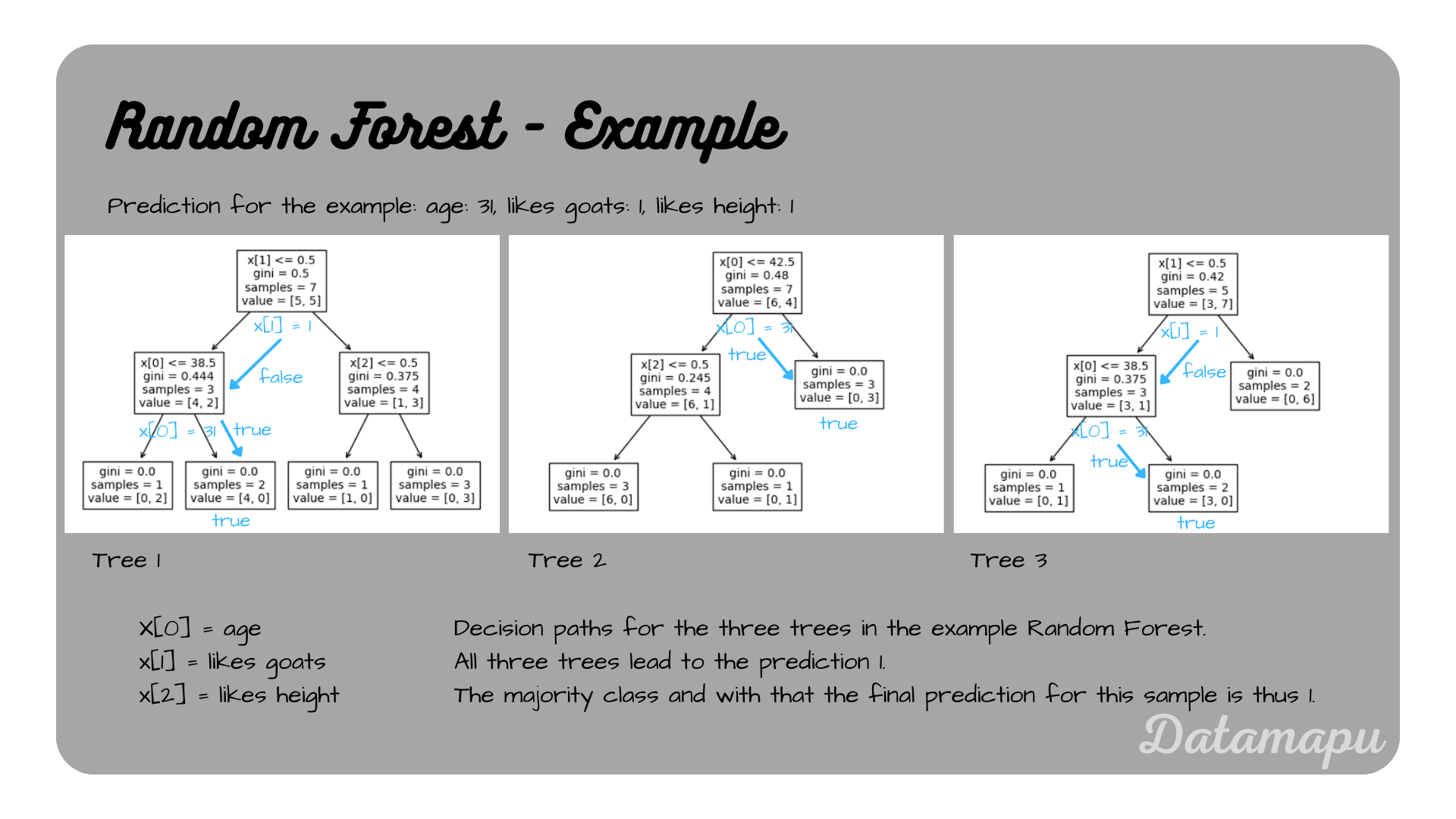 Decision paths for the second sample for each tree for the example.
Decision paths for the second sample for each tree for the example.
Using the predict method, we can print the predictions of the Random Forest classifier directly for this sample.
| |
This leads to Predictions: [1], confirming our manual calculations.
Hyperparameters
We already used the hyperparameter n_estimators in the previous example. Sklearn offers a lot of hyperparameters, that we can use to optimize a Random Forest. Important ones are:
- n_estimators: Number of Decision Trees used to create the Random Forest (default: 100).
- criterion: Function used to define the best split (default: Gini Impurity).
- max_depth: Maximum depth of the trees (default: None, i.e. the trees are expanded until all leaves are pure).
- min_sample_split: Minimum number of samples to split a node (default: 2).
- min_samples_leaf: Minimum number of samples required to become a leaf node (default: 1).
- max_features: Maximum number of features considered to find the best split (default: the squareroot of the total number of features).
- bootstrap: Whether bootstrapping is used or not (default: True). If set to False, the entire dataset is used for each tree.
A complete list with detailed explanations of all possible hyperparameters can be found in the sklearn documentation. For regression tasks the Procedure is analogue, the used method in sklearn is called RandomForestRegressor and a detailed list of all hyperparameters can be found in the sklearn documentation.
Evaluation
The example above is only to illustrate how to fit a Random Forest in Python. In practice, we would first divide the dataset into training, validation, and test sets, before fitting and evaluating the model. You can find a more realistic example with a larger dataset on kaggle.
The evaluation of a Random Forest model depends on whether a classification or a regression problem is considered. In any case, the common metrics can be used to evaluate the results. You can find an overview of the most common metrics in the articles Metrics for Classification Problems or Metrics for Regression Problems
Summary
In this article we learned about Random Forests, how they are created, and their main advantages and disadvantages. Random Forests are an ensemble Machine Learning model consisting of multiple Decision Trees. They use the strength of Decision Trees and at the same time overcome their tendency to overfit. Compared to Decision Trees, Random Forests are more robust, flexible, and accurate, they lose however interpretability and are more expensive to train. For a more realistic example with a larger dataset, check this kaggle notebook.
If this blog is useful for you, I’m thankful for your support!
