Ensemble Models - Illustrated
- 3 minutes read - 573 wordsIntroduction
In Ensemble Learning multiple Machine Learning models are combined into one single prediction to improve the predictive skill. The individual models can be of different types or the same. Ensemble learning is based on “the wisdom of the crowds”, which assumes that the expected value of multiple estimates is more accurate than a single estimate. Ensemble learning can be used for regression or classification tasks. Three main types of Ensemble Learning method are most common.
Bagging / Bootstrap Aggregation
In Bagging several random samples are drawn from the training data with replacement, this is called bootstrapping. Next, for each of these sets, a model is trained for the task of interest. These models are homogenous and independent of each other, i.e. they can be trained in parallel. If a classification problem is considered, the final prediction is the majority vote of all predictions, that is the class mostly predicted by the single models. If a regression problem is considered, the final prediction is the mean of all predictions.
Bagging is often used to reduce the variance compared to a single model. The most famous example of bagging is the Random Forest, which uses a set of Decision Trees to make a combined prediction.
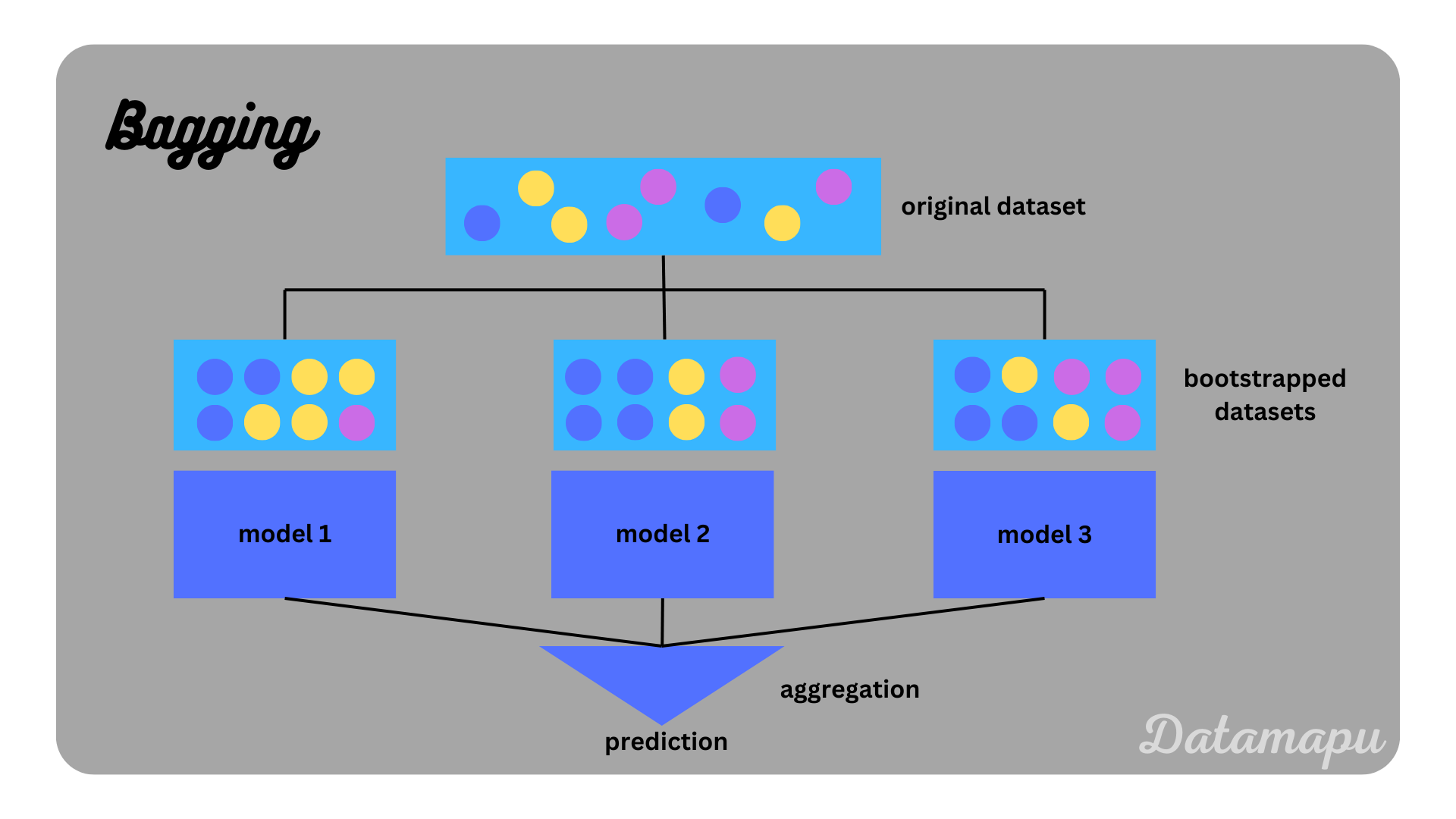 Bagging illustrated.
Bagging illustrated.
Boosting
In Boosting the individual models are trained sequentially and not in parallel. Each newly trained model builds on the previous one and aims to correct its errors. This can be done in different ways. One possibility is to give the wrongly predicted values more weight. This method is e.g. used in the AdaBoost algorithm. In the plot below, this is illustrated by a stronger color for data samples with more weight. Another possibility to achieve this is to reduce the residuals of the previous model. This is e.g. used in Gradient Boosting or XGBoost. The models combined in boosting are homogenous and so-called weak learners, which means their predictive skill is low and only slightly higher than random guessing. Considering Decision Trees as an example a weak learner is a very shallow tree or even only the stump. The stump only includes the root node and the first split. The objective is to combine a set of weak learners to a single strong learner, that is to a model with high predictive skill. Boosting is often used to achieve a larger variance and a smaller bias compared to the ones of the weak learners.
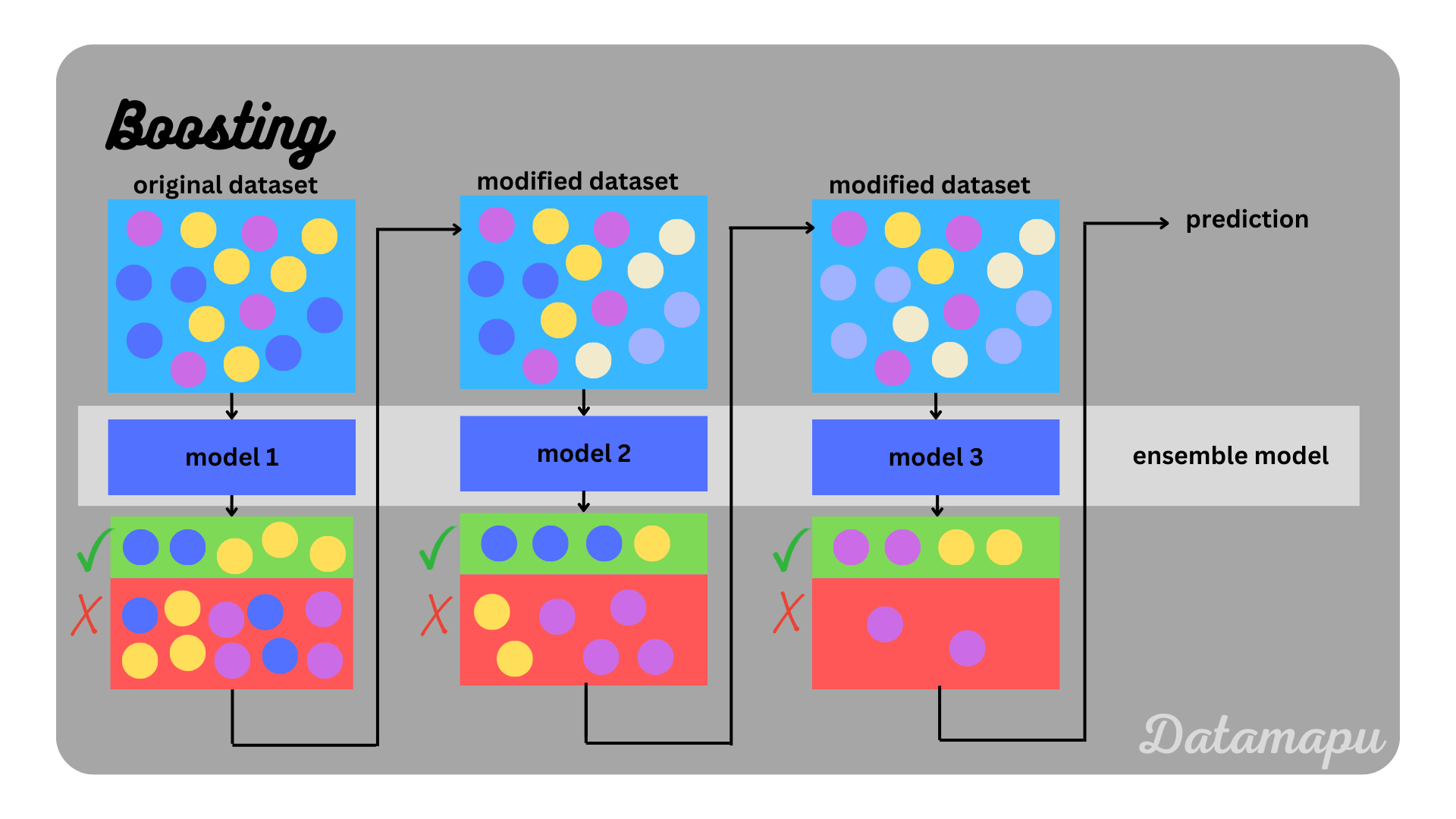 Boosting illustrated.
Boosting illustrated.
Stacking
In stacking the set of models trained is heterogenous, the output of which is used as an input to an aggregation model, also called meta model, which provides the final prediction. More levels of models are possible in stacking, two levels, however, are the most common approach. There are no rules for the types of models used in each level, it is however common to use a relatively simple model as the aggregation model, e.g. a Logistic Regression or Linear Regression. Usually, a diverse set of base models is used, which produces uncorrelated prediction errors and the individual models complement each other.
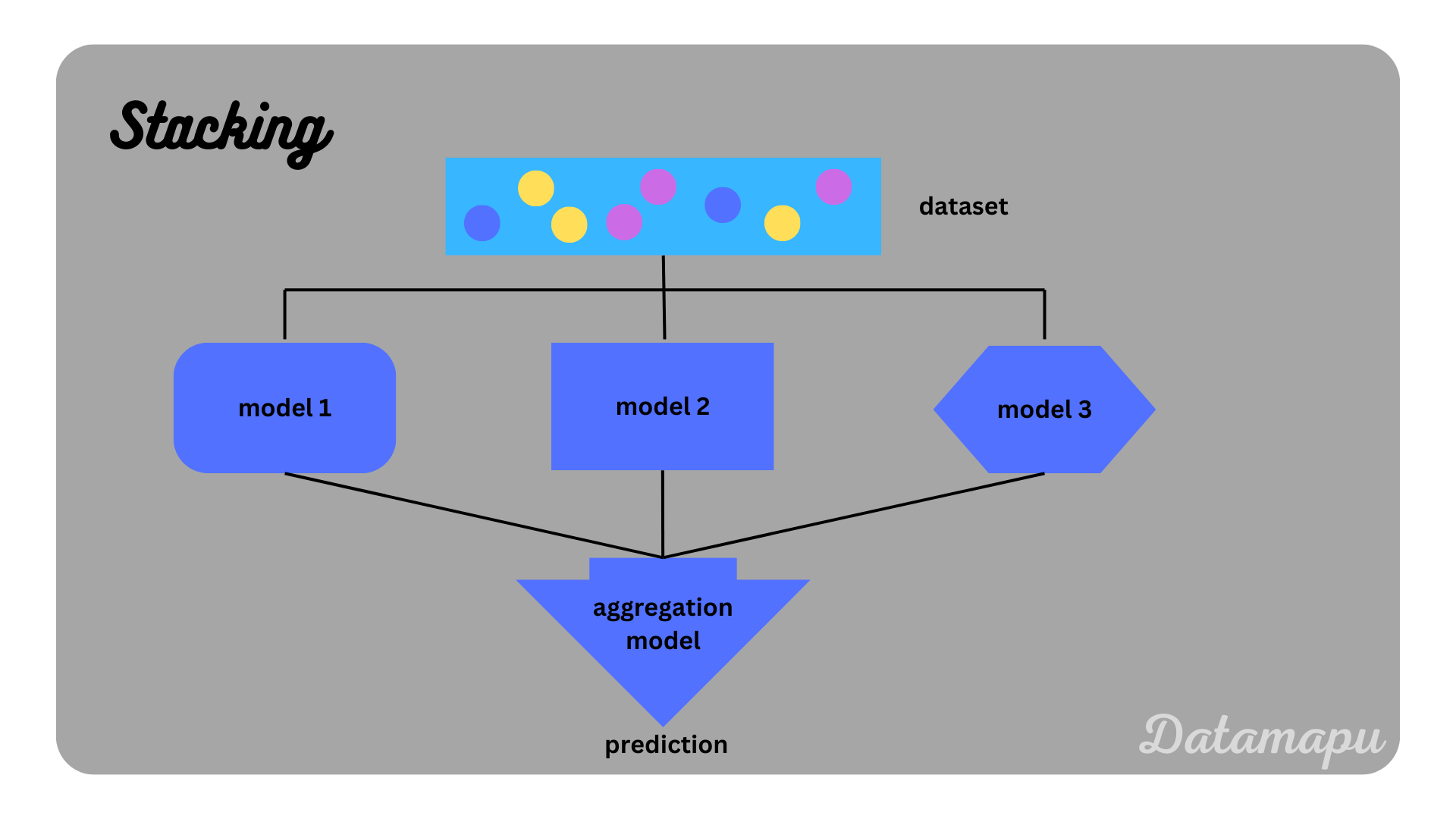 Stacking illustrated.
Stacking illustrated.
Summary
In this post, we learned about the three main types of ensemble models in Machine Learning, which are Bagging, Boosting, and Stacking. However, there exist more ensemble methods than these three. Ensemble models are often used because they improve the predictive skill compared to the individual models and better generalize to new unseen data.
If this blog is useful for you, please consider supporting.
