Gradient Boost for Classification Example
- 8 minutes read - 1548 wordsIntroduction
In this post, we develop a Gradient Boosting model for a binary classification. We focus on the calculations of each single step for a specific example chosen. For a more general explanation of the algorithm and the derivation of the formulas for the individual steps, please refer to Gradient Boost for Classification - Explained and Gradient Boost for Regression - Explained. Additionally, we show a simple example of how to apply Gradient Boosting for classification in Python.
Data
The dataset used for this example contains 10 samples and describes the task of whether a person should go rock climbing depending on their age, and whether the person likes height and goats. The same dataset was used in the articles Decision Trees for Classification - Example, and Adaboost for Classification - Example.
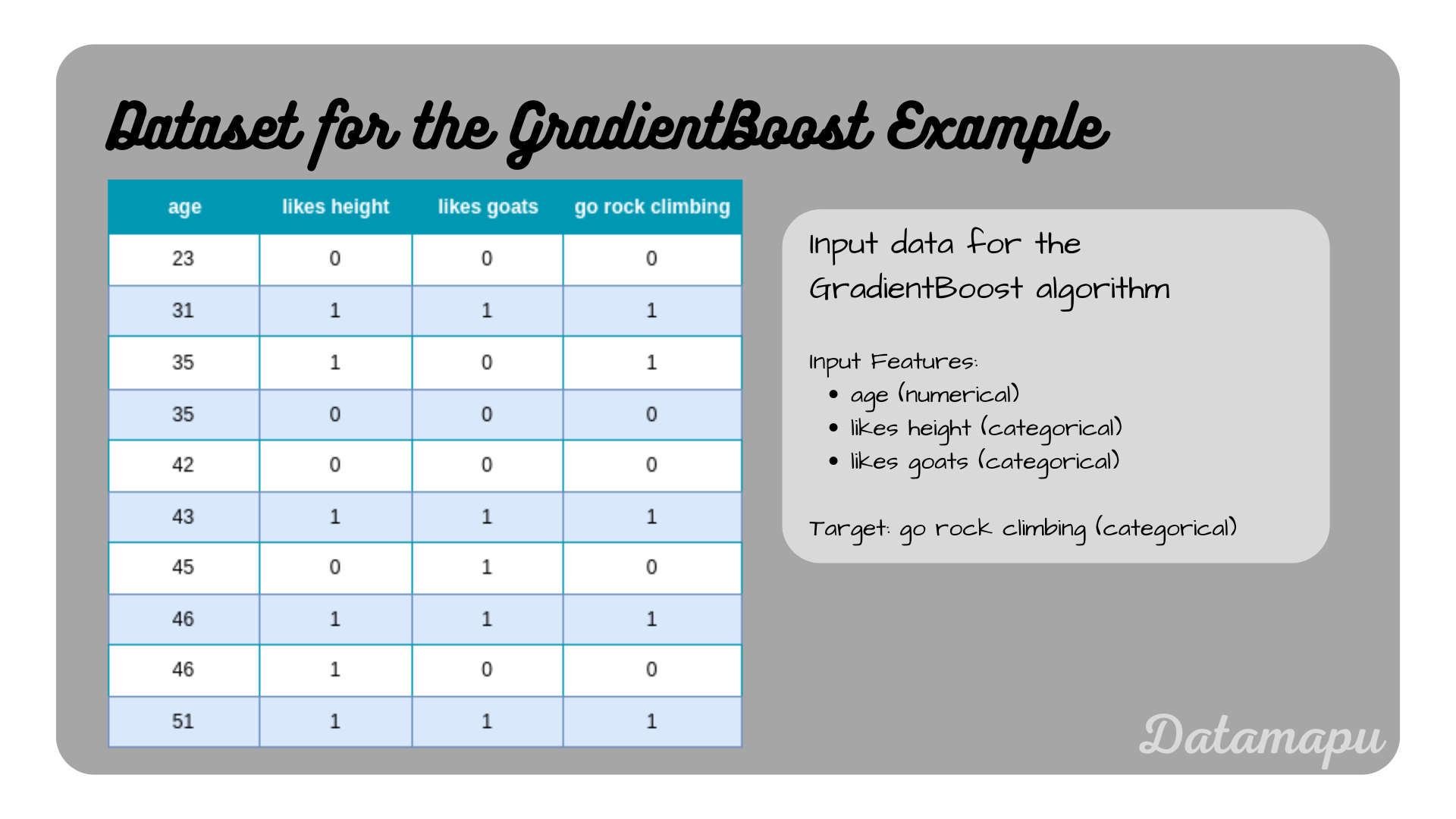 The data used in this post.
The data used in this post.
Build the Model
We build a Gradient Boosting model using pruned Decision Trees as weak learners for the above dataset. The steps to be performed are summarized in the plot below. For a more detailed explanation please refer to Gradient Boost for Classification - Explained.
 Gradient Boosting Algorithm simplified for a binary classification task.
Gradient Boosting Algorithm simplified for a binary classification task.
Step 1 - Initialize the model with a constant value - $F_0(X) = \log\Big(\frac{p}{1-p}\Big)$.
For the first initialization, we need the probability of “go rock climbing”. In the above dataset, we have five $1$s and five $0$s, and a total dataset size of ten samples. That is the probability of “going rock climbing” is $\frac{5}{10} = 0.5$. With that, we can calculate
$$F_0(X) = \log\Big(\frac{P(y=1)}{P(y=0)}\Big) =\log\Big(\frac{0.5}{0.5}\Big) = 0.$$
The initial log-loss in this case is $0$, which means that the chances of both outcomes of the target variable are equal. The initial predictions are thus $$F_0(X) = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]$$
To check the performance of our model, we use the accuracy score. We calculate the accuracy after each step, to see how the model evolves. For the initial predictions, we first calculate the probabilities.
$$p_0 = \frac{1}{1 + e^{-F_0(X)}} = [0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5]$$
As a threshold for predicting a $1$ we use $0.5$. In this case, the predictions are
$$\hat{y}_0 = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]$$.
The accuracy is calculated as the fraction of the correct predicted values and the total number of samples
$$accuracy = \frac{5}{10} = 0.5$$
Step 2 - For $m=1$ to $M=2$:
In this step we sequentially fit weak learners (pruned Decision Trees) to the residuals. The number of loops is the number of weak learners considered. Because the data considered in this post is so simple, we will only loop twice, i.e. .
First loop $M=1$
Fit the first Decision Tree.
2A. Compute the residuals of the preditions and the true observations.
The residuals are calculated as
$$r_1 = y - p_0 = [-0.5, 0.5, 0.5, -0.5, -0.5, 0.5, -0.5, 0.5, -0.5, 0.5]$$
2B. and 2C. Fit a model (weak learner) to the residuals and find the optimized solution.
In this step, we use the above calculated residuals to fit a Decision Tree. We prune the tree to use it as a weak learner. We use a maximum depth of two. We don’t develop the Decision Tree by hand, but will use the sklearn method DecisionTreeClassifier. For a step-by-step example of building a Decision Tree for Classification, please refer to the article Decision Trees for Classification - Example.
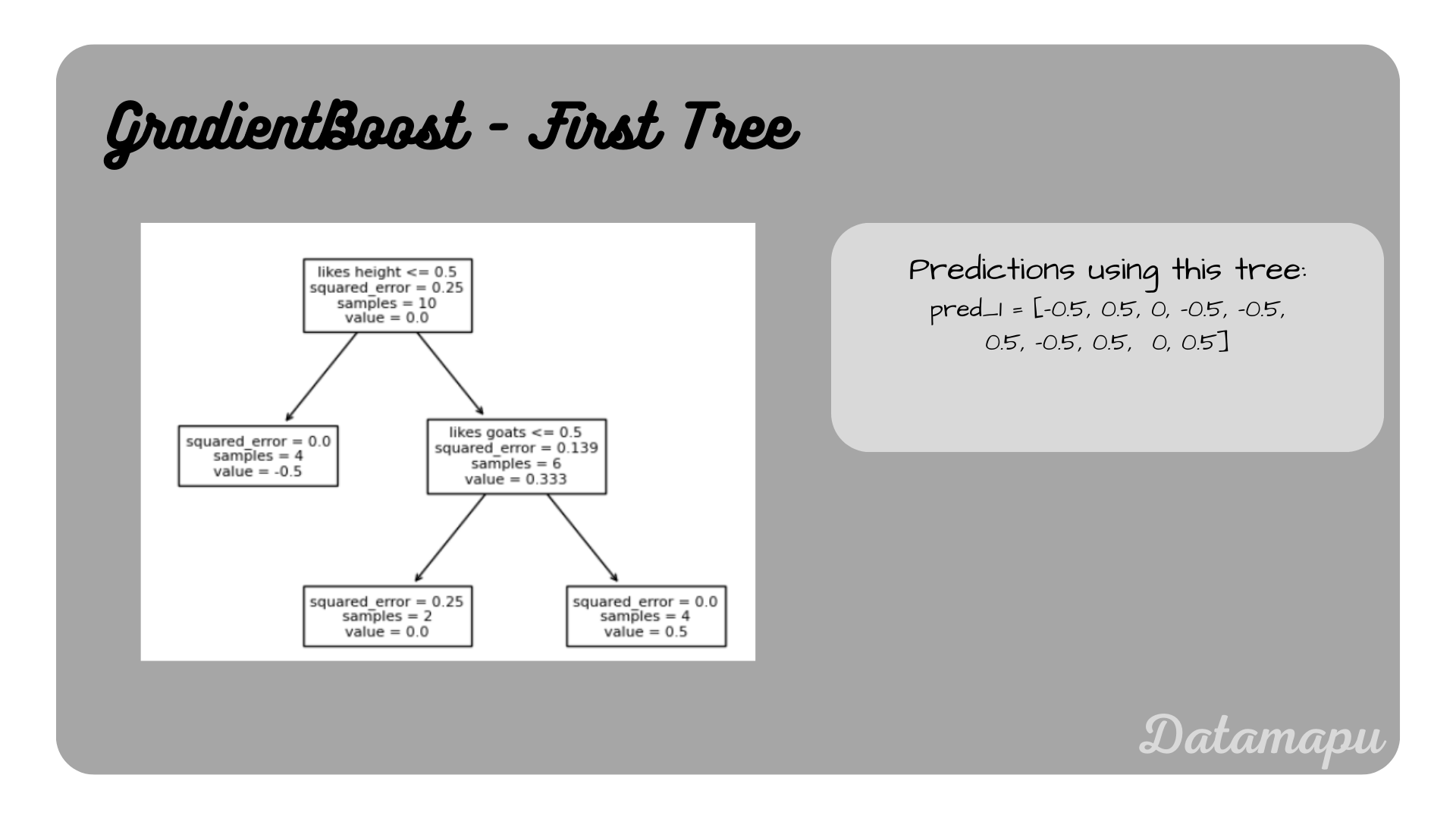 First Decision Tree, i.e. first weak learner
First Decision Tree, i.e. first weak learner
The resulting predictions are
$$pred_1(X) = [-0.5, 0.5, 0. , -0.5, -0.5, 0.5, -0.5, 0.5, 0. , 0.5]$$
2D. Update the model.
We update the model using the predictions of the above developed Decision Tree. We use a learning rate of $\alpha = 0.3$ for this example. This results in the updated model
$$F_1(X) = F_0(X) + 0.3 * pred_1(X).$$
Using the calculated numbers, this leads to
$$F_1(X) = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0] + 0.3 \cdot [-0.5, 0.5, 0. , -0.5, -0.5, 0.5, -0.5, 0.5, 0. , 0.5]$$ $$F_1(X) = [-0.15, 0.15, 0, -0.15, -0.15, 0.15, -0.15, 0.15, 0, 0.15]$$
The probabilies resulting from these log-loss are
$$p_1 = \frac{1}{1 + e^{-F_1(X)}} = [0.46, 0.54, 0.5, 0.46, 0.46, 0.54, 0.46, 0.54, 0.5, 0.54].$$
With the threshold of $0.5$ this leads to the predictions
$$\hat{y}_2(X) = [0, 1, 1, 0, 0, 1, 0, 1, 1, 1].$$
The accuracy after this step is
$$accuracy = \frac{9}{10} = 0.9.$$
Second loop $M=2$
Fit the second Decision Tree.
2A. Compute the residuals of the preditions and the true observations
The residuals are calculated as
$$r_2 = y - p_1 = [-0.46, 0.46, 0.5, -0.46, -0.46, 0.46, -0.46, 0.46, -0.5, 0.46]$$
2B. and 2C. Fit a model (weak learner) to the residuals and find the optimized solution.
Now we fit the second Decision Tree with the residuals $r_2$ calculated above as target.
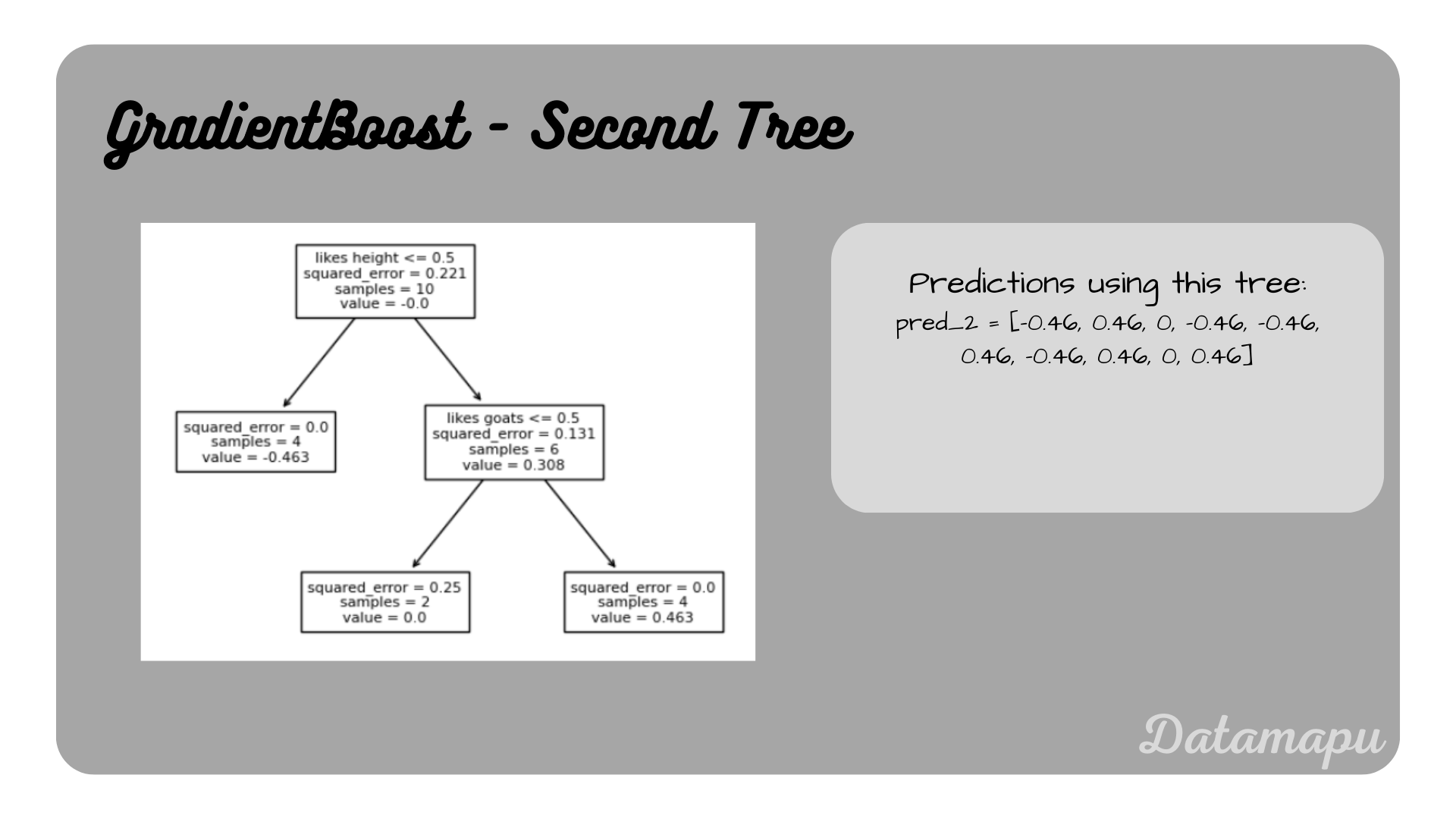 Second Decision Tree, i.e. second weak learner
Second Decision Tree, i.e. second weak learner
The resulting predictions are
$$pred_2(X) = [-0.46, 0.46, 0, -0.46, -0.46, 0.46, -0.46, 0.46, 0, 0.46]$$
2D. Update the model.
We again update the model using the predictions of this second Decision Tree with a learning rate of $0.3$. This results in the updated model
$$F_2(X) = F_1(X) + 0.3 \cdot pred_2(X).$$
Using the calculated numbers, this leads to
$$F_2(X) = [-0.15, 0.15, 0, -0.15, -0.15, 0.15, -0.15, 0.15, 0, 0.15] + $$ $$0.3 \cdot [-0.46, 0.46, 0, -0.46, -0.46, 0.46, -0.46, 0.46, 0, 0.46]$$ $$F_2(X) = [-0.29, 0.29, 0, -0.29, -0.29, 0.29, -0.29, 0.29, 0, 0.29]$$
The probabilies resulting from these log-loss are
$$p_2 = \frac{1}{1 + e^{-F_2(X)}} = [0.43, 0.57, 0.5, 0.43, 0.43, 0.57, 0.43, 0.57, 0.5, 0.57].$$
With the threshold of $0.5$ this leads to the predictions
$$\hat{y}_3 = [0, 1, 1, 0, 0, 1, 0, 1, 1, 1].$$
The accuracy after this step is
$$accuracy = \frac{9}{10} = 0.9.$$
That is, this second step didn’t improve the accuracy of our model.
Step 3 - Output final model $F_M(x)$.
The final model then in defined by the output of the last step
$$F_2(X) = F_0(X) + \alpha \cdot F_1(X) + \alpha \cdot pred_2.$$
Using the input features $X$ given in the above table, this is
$$F_2(X) = [-0.29, 0.29, 0, -0.29, -0.29, 0.29, -0.29, 0.29, 0, 0.29].$$
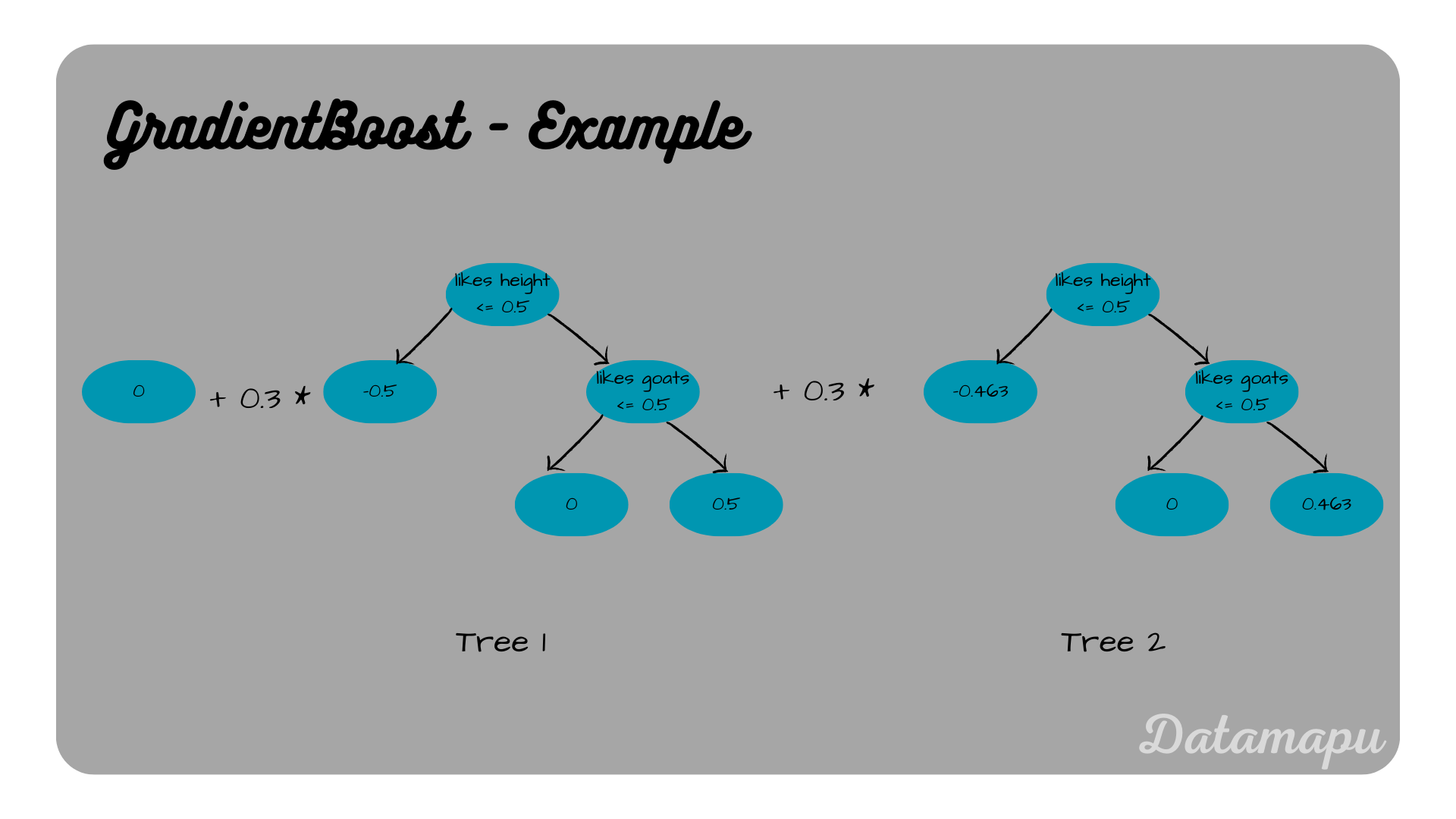 Final model.
Final model.
Accordingly the final probabilities $p_2$ and predictions $\hat{y}_3$ as calculated in the last step of the above loop.
Fit a Model in Python
In this section, we will show how to fit a GradientBoostingClassifier from the sklearn library to the above data. In sklearn the weak learners are fixed to Decision Trees and cannot be changed. The GradientBoostingClassifier offers a set of hyperparameters, that can be changed and tested to improve the model. Note, that we are considering a very simplified example. In this case, we set the number of weak learners (n_estimators) to $2$, the maximal depth (max_depth) of the Decision Trees to $2$, and the learning_rate=$0.3$. For real-world data, usually, hyperparameters are chosen differently, the default values in sklearn are n_estimators$=100$, max_depth$=3$, and the learning_rate=$0.1$. For a complete list of available hyperparameters, please refer to the sklearn documentation.
We read the data into a Pandas dataframe.
| |
Now we can fit the model using the above defined hyperparameters.
| |
The GradientBoostingClassifier has a predict method, which we can use to get the predictions and the score method to calculate the accuracy.
| |
We get the predictions $[0, 1, 0, 0, 0, 1, 0, 1, 0, 1]$ and a score of $0.9$. A more detailed example of applying Gradient Boosting in Python can be found on kaggle - this is an example of a regression problem. The application to a classification problem, however, is the same, we only need to change the GradientBoostingRegressor to the GradientBoostingClassifier and change the metrics to evaluate the model.
Summary
In this post, we went through the calculations of the individual steps to build a Gradient Boosting model for a binary classification problem. A simple example was chosen to make explicit calculations feasible. Later, we showed how to fit a model using Python. In real-world examples, libraries like sklearn are used to develop such models. The development is usually not as straightforward as in this simplified example, but a set of hyperparameters are (systematically) tested to optimize the solution. For a more detailed explanation of the algorithm, please refer to the related articles Gradient Boost for Classification - Explained, Gradient Boost for Regression - Explained, Gradient Boost for Regression - Example. For a more practical approach, please check the notebook on kaggle, where a Gradient Boosting model for a regression problem is developed.
If this blog is useful for you, please consider supporting.
