Gradient Boosting Variants - Sklearn vs. XGBoost vs. LightGBM vs. CatBoost
- 11 minutes read - 2217 wordsIntroduction
Gradient Boosting is an ensemble model of a sequential series of shallow Decision Trees. The single trees are weak learners with little predictive skill, but together, they form a strong learner with high predictive skill. For a more detailed explanation, please refer to the post Gradient Boosting for Regression - Explained. In this article, we will discuss different implementations of Gradient Boosting. The focus is to give a high-level overview of different implementations and discuss the differences. For a more in-depth understanding of each framework, further literature is given.
Background
Gradient Boosting in sklearn
Gradient Boosting is one of many available Machine Learning algorithms available in sklearn, which is short for scikit-learn. sklearn started as a Google summer of code project by David Cournapeau and was originally called scikits.learn. The first version was published in 2010 by the contributors Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, and Vincent Michel, from the French Institute for Research in Computer Science and Automation in Saclay, France. Nowadays it is one of the most extensive and used libraries in Machine Learning.
XGBoost
XGBoost stands for eXtreme Gradient Boosting and is an algorithm focusing on optimizing computation speed and model performance. XGBoost was first developed by Tianqi Chen. It became popular and famous for many winning solutions in Machine Learning competitions. XGBoost can be used as a separate library, but also as an integration in sklearn. This makes it easy to combine the variety of methods available in sklearn. The XGBoosts algorithm is capable of handling large and complex datasets.
LightGBM
LightGBM is short for Light Gradient-Boosting Machine, and was developed by Microsoft. It has similar advantages as XGBoost and is also able to handle large and complex datasets. The main difference between LightGBM and XGBoost is the way the trees are built. In LightGBM the trees are not grown level-wise, but leave-wise.
CatBoost
CatBoost was developed by Yandex, a Russian technology company and has a special focus on how categorical values are treated in Gradient Boosting. It was developed in 2016 and was based on previous projects focussing on Gradient Boosting algorithms. It was first released open-source in 2017.
Feature Handling
Gradient Boosting in sklearn
Numerical Features: Gradient Boosting in sklearn expects numerical input.
Categorical Features: Gradient Boosting in sklearn does not natively support categorical features. They need to be encoded using e.g. one-hot encoding or label-encoding.
Missing Values: Gradient Boosting in sklearn does not handle missing values. Missing values need to be removed or imputed before training the model.
Histogram-based Gradient Boosting by sklearn was inspired by LightGBM.
Numerical & Categorical Features: The Histogram-based Gradient Booster natively supports numerical and categorical features. For more details, please check the documentation.
Missing Values: The Histogram-based Gradient Booster can handle missing values natively. More explanations can be found in the documentation.
XGBoost
Numerical Features: XGBoost supports directly numerical data.
Categorical Features: Both the native environment and the sklearn interface support categorical features using the parameter enable_categorical. Examples of both interfaces can be found in the documentation.
Missing Values: XGBoost natively supports missing values. Note, that the treatment of missing values differs with the booster type used. For more explanations, please refer to the documentation.
LightGBM
Numerical Features: LightGBM supports numerical data.
Categorical Features: LightGBM has built-in support for categorical features. Categorical features can be specified using the parameter categorical_feature. For more details, please refer to the documentation.
Missing Values: LightGBM natively supports the handling of missing values. It can be disabled using the parameter use_missing=false. More information is available in the documentation.
CatBoost
Numerical Features: CatBoost supports numerical data.
Categorical Features: CatBoost is specifically designed to handle categorical features without needing to preprocess them into numerical formats. How this transformation is done, is described in the documentation
Missing Values: CatBoost has robust handling for missing values, treating them as a separate category or using specific strategies for imputation during training. How missing values are treated depends on the feature type. More details can be found in the documentation
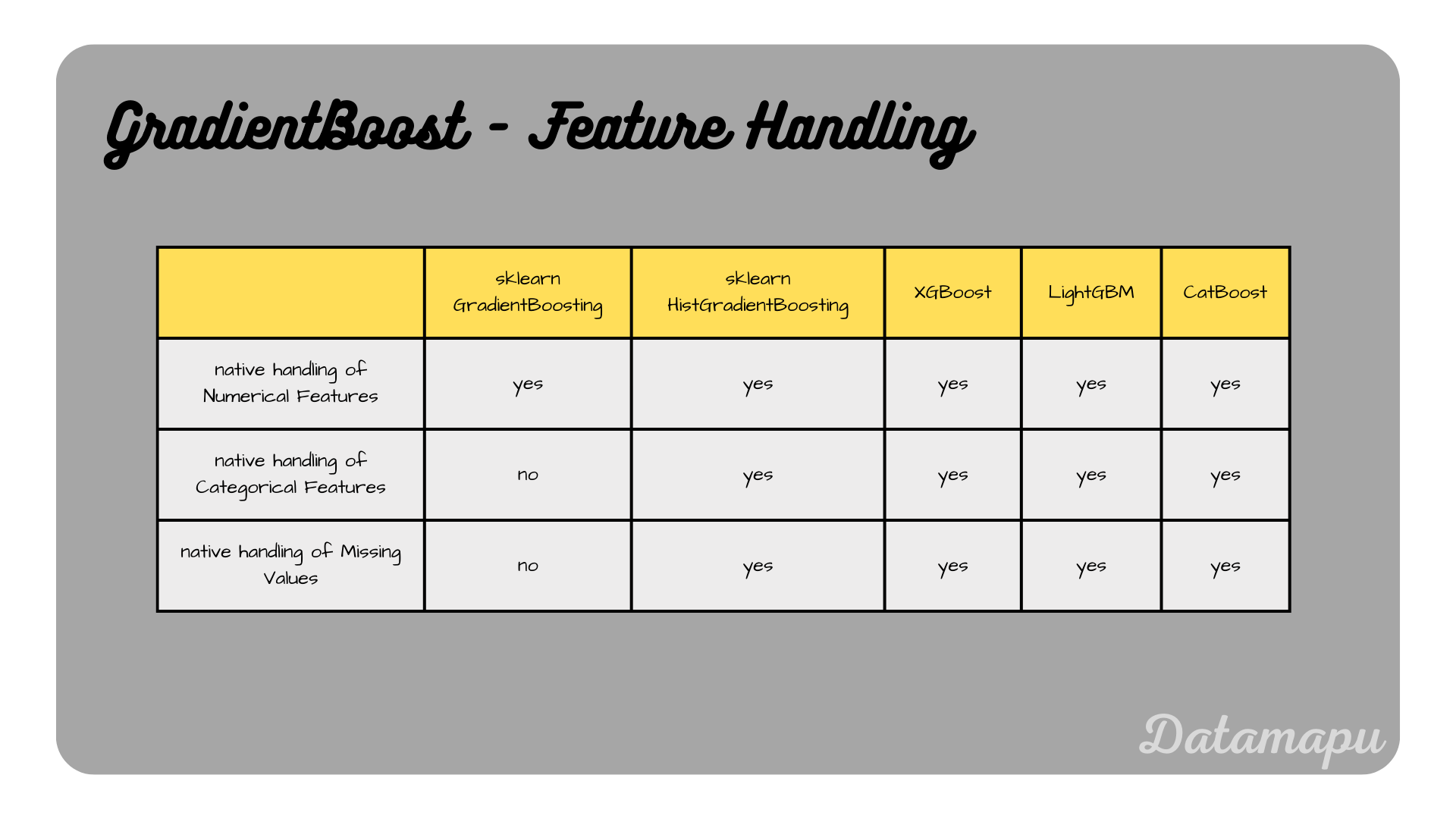 Feature handling in the different implementations.
Feature handling in the different implementations.
Tree Growths
Traditionally Decision Trees are grown level-wise. That means first a level is developed completely, such that all leaves are grown before moving to the next level. An alternative approach is leaf-wise tree growth. In this case, this criterion is relaxed and the tree is grown with the highest loss reduction considering all leaves, which may result in unsymmetric, irregular trees of larger depth. The different methods are illustrated in the plot below. The leaf-wise tree is built using the global best split, while the level-wise growth only uses a local minimum for the next split, also leaf-wise growth is computationally more efficient and less memory intensive.
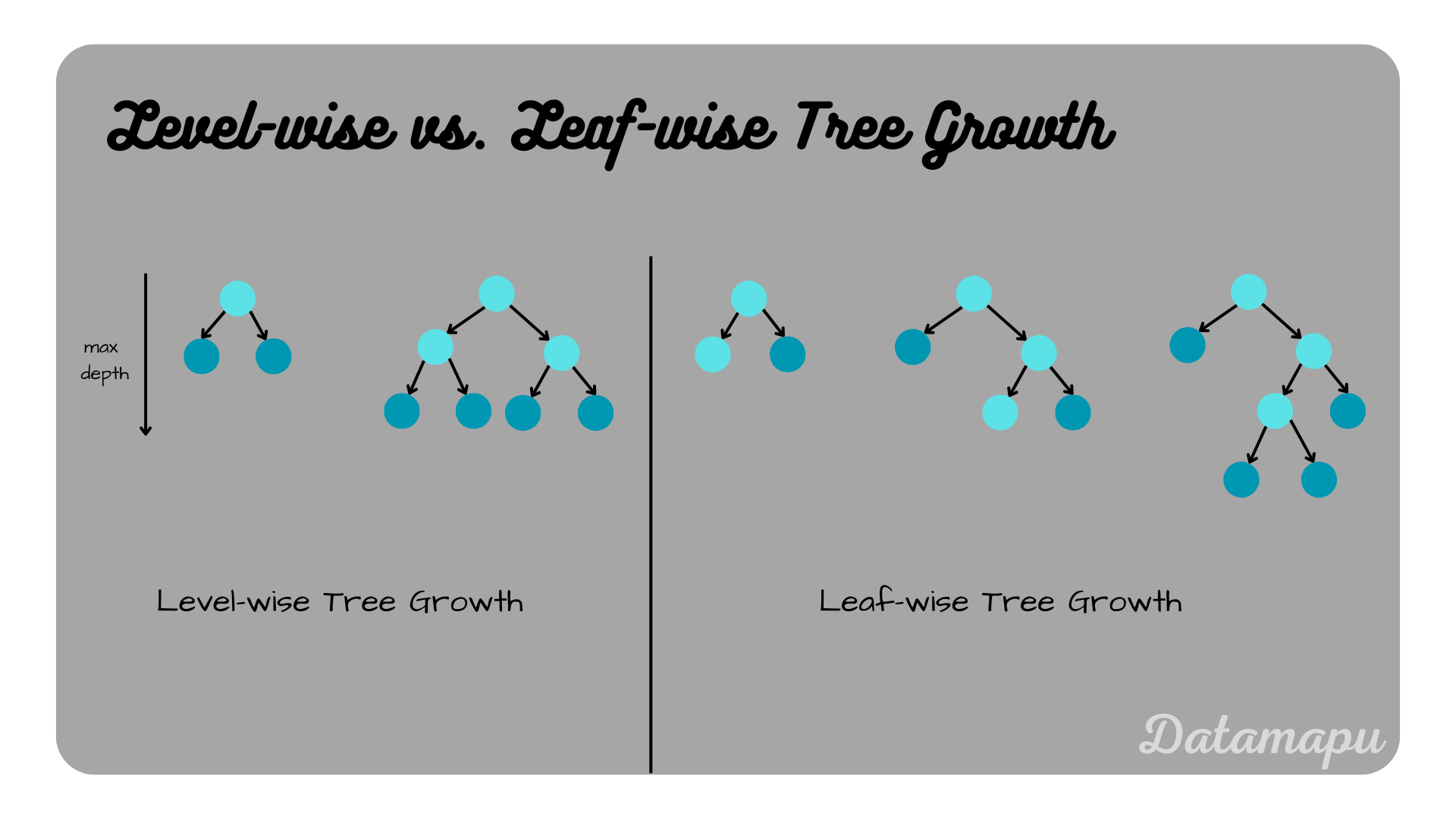 Level-wise and leaf-wise Tree Growth illustrated.
Level-wise and leaf-wise Tree Growth illustrated.
Gradient Boosting in sklearn
In the Gradient Boosting algorithm of sklearn the trees are grown level-wise, that is they are grown level by level, expanding all nodes at a given depth before moving deeper. This produces balanced trees and can be slower and more memory-intensive.
In HistGradientBossting histograms are used to approximate the data distributions, and then the trees are grown level by level. This algorithm is faster and more efficient with large datasets compared to traditional Gradient Boosting.
XGBoost
The trees in XGBoost are also grown level-wise, but advanced algorithms are used to find the optimal split and regularization, which improves computational efficiency. XGBoost offers the possibility to use histogram-based splitting.
LightGBM
In LightGBM the trees are grown leaf-wise. This produces unbalanced and deeper trees, but is in general faster and more efficient.
CatBoost
CatBoost uses symmetric tree growth. Symmetric trees are grown by splitting all leaves at the same depth identically.
Overfitting
sklearn
Traditional Gradient Boosting and Histogram-based Gradient Boosting both use regularization, learning rate adjustment, subsampling, and early stopping to combat overfitting. However, Histogram-based Gradient Boosting’s binning process adds an extra layer of complexity reduction and efficiency, making it particularly effective for large datasets.
XGBoost
Combines regularization, shrinkage, early stopping, and tree pruning.
LightGBM
Employs leaf-wise growth with depth limits, regularization, and early stopping.
CatBoost
CatBoost uses Ordered Boosting and regularization to prevent overfitting.
GPU Support
The implementations of XGBoost, LightGBM, and CatBoost support GPU usage, which enhances performance and speed on large datasets compared to the sklearn implementations.
Code Examples
In this section a brief example of each method is given for a classification task, however, all models have variants for regression problems. The dataset used is described in the plot below. The example used here is very simple and only for illustration purposes. More detailed examples on a larger dataset can be found on kaggle.
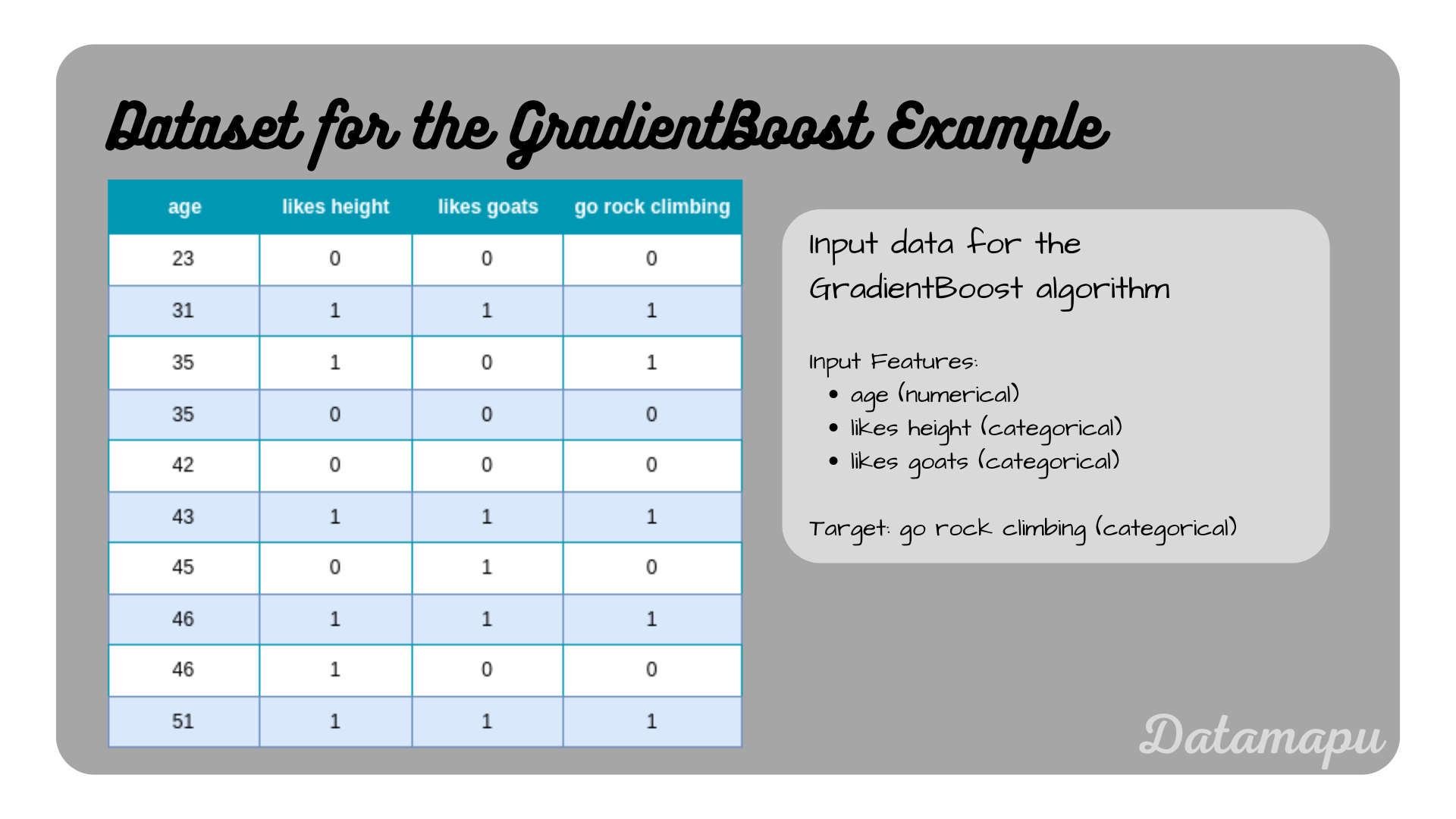 The data used for the following examples.
The data used for the following examples.
We read this data into a Pandas dataframe
| |
Gradient Boosting in sklearn
For the installation of sklearn please check the official documentation. We have different options using conda or pip, which may differ depending on your operating system. All details can be found there. To use the GradientBoostingClassifier, we need to import it from sklearn. With the input features $X$ and the target data $y$ defined, we can fit the model. First, we need to instantiate it and then following the concept of training Machine Learning models in sklearn, we can use the fit method. The process is illustrated in the following code snipped. In this example, three hyperparameters are set: n_estimators, which describes the number of trees used, max_depth; which is the depth of the single trees; and the learning_rate, which defines the weight of each tree. A full list of hyperparameters, that can be changed to optimize the model can be found in the documentation of the GradientBoostingRegressor and the GradientBoostingClassification methods.
| |
We can use the predict method to get the predictions and the score method to calculate the accuracy.
| |
A more detailed example of applying Gradient Boosting in Python to a Regression task can be found on kaggle.
XGBoost
The installation is described in detail in the XGBoost documentation.
To use the XGBoostClassifier, we need to import this method. The procedure is the same as for the sklearn model. We instantiate the model and then use the fit and predict method. A detailed list of all possible parameters can be found in the XGBoost documentation. There are three types of parameters: general parameters, booster parameters, and task parameters. The following gives a brief explanation of each category but is not an exhaustive list.
- General parameters define which booster is used. By default this is a Gradient Boosting Tree; the same as in the sklearn method, other options are dart and gblinear. The methods gbtree and dart are tree-based models, gblinear is a linear model. Other parameters set here refer to the device used (cpu or gpu), the number of threads used for training, verbosity, and several more.
- Booster parameters depend on which booster method is used. For a Tree Booster, we can e.g. choose the number of estimators (n_estimators), the learning rate (learning_rate or eta), the maximal depth of the trees (max_depth), and many more. Further, the type of tree method to use can be changed to optimize the speed.
- Learning task parameters depend on the task to be solved. The objective function and the evaluation metrics are defined here, which depend on whether we consider a regression or a classification task. There is a wide variety of pre-defined objective functions and metrics for both types of problems are available, but we can also define custom functions. For more details, please refer to this post.
| |
XGBoost also allows the use of callbacks, such as early stopping, or customized callbacks. A more detailed example using XGBoost with different parameters and callbacks on a larger dataset can be found on kaggle.
LightGBM
A guide for the installation can be found in the LightGBM documentation.
As in the previous models, we define the input features $X$ and the target value $y$, then we instantiate the model, fit it to the data, and make predictions. A full list of possible parameters can be found in the documentation. We can define a large set of different types of parameters, considering the core functionality, the control of the learning, the dataset, the metrics, and more. Similar to XGBoost, LightGBM allows us to choose between different boosting methods. The default method is Gradient Boosting Trees In this example we set the number of estimators (n_estimators), the maximal depth of the Decision Trees (max_depth), the learning rate (learning_rate), and the maximal number of leaves (num_leaves).
| |
LightGBM allows an easy implementation of e.g. early stopping and cross validation using callbacks. For a more detailed example on a larger dataset, please check this kaggle notebook.
CatBoost
Using CatBoost, the procedure of training and predicting is the same as in the previous examples: instantiate the model, fit it to the data, and make predictions. A full list of all possible parameters is in the documentation. For this example, we set iterations, which refers to the number of trees trained, the learning_rate, and the depth, which defines the maximal depth of the Decision Trees.
| |
For a more realistic example on a larger dataset, please refer to this kaggle notebook, which describes a regression problem.
Summary
Gradient Boosting is a popular and performant algorithm for both classification and regression tasks. In this post we compared different implementations of this algorithm, comparing the method the individual trees are grown, but also their ability to handle categorical features and missing values. The main characteristics are that LightGBM uses a leaf-wise tree growth strategy in contrast to the other algorithm and CatBoost was specifically designed to handle categorical features. However other algorithms also offer native support for categorical features. The implementations of XGBoost, LightGBM, and CatBoost additionally support the usage of a GPU, which makes them especially suitable for large datasets.
Further Reading
- Haithm H. Alshari et al., “Comparison of Gradient Boosting Decision Tree Algorithms for CPU Performance”, Journal of Institute Of Science and Technology, Volume 37, Issue 1, 2021
If this blog is useful for you, please consider supporting.
